


027-83317177
在AI狂飙的这些年里,行业几乎被一条逻辑主导:算力决定上限,而GPU就是算力的核心。
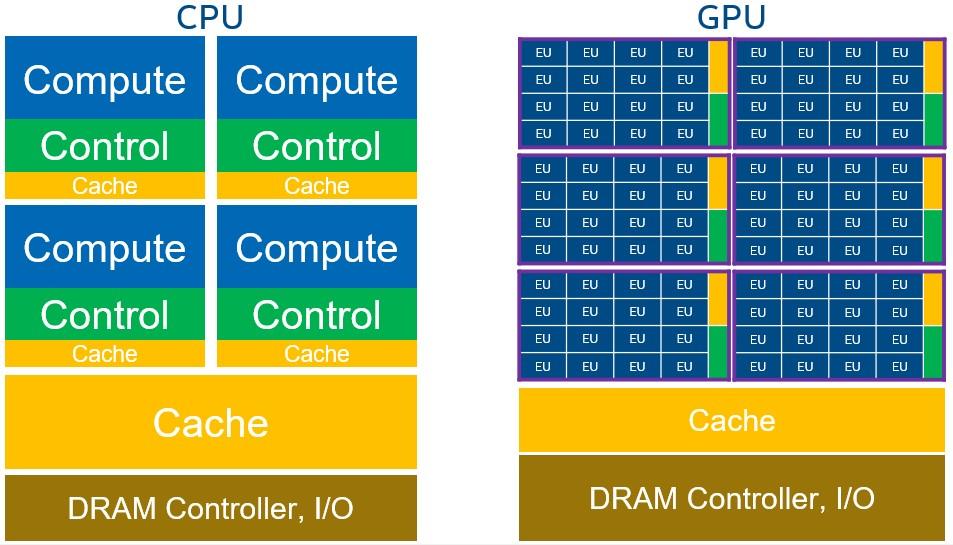
不过,进入2026年,这套逻辑开始变动:模型推理不再是唯一瓶颈,系统性能越来越取决于执行与调度能力。GPU依然重要,但决定AI“能不能跑起来”的关键,正逐渐转向长期被忽视的CPU。
美国当地时间4月9日,谷歌与英特尔达成多年协议,在全球AI数据中心规模部署英特尔的“Xeon至强处理器”,正是为了破解这个瓶颈。英特尔CEO陈立武直言,AI运行在整个系统上,CPU和IPU才是性能、效率和灵活性的关键。换句话说,过去两年被当作“配角”的CPU,正在卡住AI扩展的“脖子”。
英特尔CEO陈立武在社交媒体表示:英特尔正与谷歌深化合作,从传统CPU扩展到AI基础设施(如IPU),共同推进AI与云计算能力建设。
CPU不再只是一个被动的配套组件,而正在成为AI基础设施中的关键变量之一。
根据多家IT分销商的最新报告,2025年第四季度,服务器CPU的平均售价上涨了约30%。这种涨幅在相对成熟的CPU市场是非常罕见的。
AMD数据中心负责人福雷斯特·诺罗德(Forrest Norrod)透露,过去三个季度,CPU需求的增长速度超乎想象。目前,AMD的交付周期已经从原来的八周延长到了十周以上,部分型号甚至面临长达六个月的延迟。
这种短缺主要由于“次级效应”引发的资源挤兑。有业内人士表示,由于台积电的3nm生产线极其紧张,原本分配给CPU的晶圆产能,正不断被利润更高的GPU订单挤占。这导致了一个极具讽刺意味的局面:AI实验室拥有了足够的GPU,却发现市场上买不到足够的顶级CPU来“带”动这些显卡。
英特尔首席执行官陈立武在社交平台上证实,马斯克已委托英特尔为其在得克萨斯州的“Terafab”项目设计并制造定制芯片。这个庞大的项目旨在为xAI、SpaceX和特斯拉提供统一的计算底座。
马斯克对英特尔的信任,在很大程度上是因为英特尔正试图将自己嵌入到从地面数据中心到太空轨道计算的每一个层面。
对于英特尔来说,这无疑是一剂强心针。有行业分析师预测AMD在服务器CPU市场的收入份额将在2026年超过英特尔,但英特尔在x86生态系统中的深厚惯性和制造能力,依然是马斯克这类大客户无法忽视的筹码。
这种跨行业的深度捆绑,正让CPU市场的竞争从单纯的参数比拼,升级为生态系统和供应链稳定性的博弈。
CPU突然成为瓶颈,核心是它需要承担的工作,在智能体时代发生了根本性变化。
传统聊天机器人模式中,CPU主要负责调度和数据处理,GPU承担核心推理计算。由于计算密集型环节集中在GPU侧,整体延迟通常由GPU主导,CPU很少成为性能瓶颈。
但智能体工作负载完全不同。一个智能体需要执行多步推理、调用API、读写数据库、编排复杂业务流,并将中间结果整合为最终输出。搜索、API调用、代码执行、文件I/O和结果编排等任务,大部分落在CPU和主机系统侧。GPU负责token生成(即“思考”),而CPU负责将“思考”结果转化为实际行动。
佐治亚理工学院学者在2025年11月发表的论文《以CPU为中心的智能体型AI视角》(A CPU-Centric Perspective on Agentic AI)中,对智能体工作负载中的延迟分布进行了量化分析。研究发现,CPU端工具处理所占用的时间,占总延迟的50%至90.6%。在某些场景下,GPU已准备好处理下一批任务,而CPU仍在等待工具调用返回。
对于这类问题的解决方案之一是将KV缓存部分卸载至CPU内存。这意味着CPU不仅要管理编排和工具调用,还要协助承载显存放不下的数据。CPU内存容量、内存带宽以及CPU与GPU之间的互连速度,由此成为系统性能的关键。
因此,适合智能体时代的CPU,更需要低延迟、一致的内存访问能力,以及更强的系统级协同能力,而不是单一的核心规模扩张。
英特尔是传统服务器CPU的老大。Mercury Research的数据显示,2025年第四季度,英特尔在服务器CPU市场仍占60%的份额,AMD占24.3%,英伟达占6.2%。但英特尔这些年一直在追赶新技术,这次CPU需求的爆发对他们来说,既是机会也是考验。
英特尔现在的策略是两条腿走路。一边是继续卖至强处理器,跟谷歌这样的超大规模客户深度绑定;另一边跟SambaNova合作,推出基于至强处理器与其自研RDU加速器的组合方案,主打“不用GPU也能跑智能体推理”的卖点。至强6 Granite Rapids和18A工艺的路线图,将是检验英特尔能否翻盘的关键。
AMD则是这次CPU需求爆发中最大的受益者之一。2025年第四季度,AMD数据中心收入54亿美元,同比增长39%。第五代EPYC Turin占了服务器CPU收入的一半以上,运行EPYC的云实例部署同比增长超过50%。AMD的服务器CPU收入份额首次突破40%。
AMD CEO苏姿丰(Lisa Su)把增长原因直接归到了“智能体”的发展——智能体工作负载把任务“推回”到了传统CPU任务上。
不过,AMD在系统级协同方面仍有提升空间,缺乏类似NVLink C2C这样成熟的高速CPU-GPU互连能力。随着智能体(Agent)系统对数据交互与协同效率要求不断提高,这一环节的重要性也在逐步上升。
英伟达Grace CPU只有72个核心,而AMD EPYC和英特尔至强通常是128个。英伟达AI基础设施负责人迪昂·哈里斯(Dion Harris)解释称:“如果你是超大规模企业,你希望最大化每个CPU的核心数量,这基本上会降低成本,即每核心的美元成本。所以这是一种商业模式。”
换句话说,在AI算力体系里,CPU的角色不再是通用计算主力,而是为GPU服务的“调度中枢”。如果CPU跟不上,昂贵的GPU就会被迫等待,整体效率反而下降。
因此,英伟达在设计上优先保证CPU与GPU之间的高效协同。例如通过NVLink C2C互连,将CPU与GPU之间的带宽提升到约1.8TB/s,远高于传统PCIe,CPU可以直接访问GPU内存,KV缓存管理一下子简单了很多。
目前,英伟达已将Vera CPU作为独立产品销售。CoreWeave是第一个客户。与Meta的交易更夸张,这是其第一次大规模“纯Grace部署”,也就是CPU在没有GPU配对的情况下大规模独立部署。
研究机构Creative Strategies首席分析师本·巴贾林(Ben Bajarin)指出,在高强度的系统协作中,CPU的处理能力必须能够匹配加速器的迭代速度。如果数据通道出现哪怕百分之一的延迟,整个AI集群的经济效益就会大打折扣。这种对极致系统效率的追求,正迫使所有大厂重新审视CPU的性能指标。
Constellation Research副总裁兼首席分析师霍尔格·穆勒(Holger Mueller)表示,随着AI工作负载向智能体驱动架构转变,CPU的地位正变得愈发核心。他指出:“在智能体世界中,智能体需要调用API和各类业务应用程序,这些任务最适合由CPU来完成。”
他还补充道:“目前,关于GPU和CPU谁更适合处理推理任务,尚无定论。GPU在模型训练方面占据优势,而像TPU这样的定制ASIC也有其专长。但有一点是明确的:谷歌需要采用混合处理器架构。因此,谷歌选择与英特尔展开合作是合理的”。
在最新的产业观察中,一个数据需要我们注意。在亚马逊AWS与OpenAI高达380亿美元的合作协议中,其官方也明确提到了“数千万个CPU”的扩展规模。
在过去几年,通常情况下,行业的关注焦点总是那“数十万个GPU”。然而,OpenAI等前沿实验室主动将CPU规模作为一个重要的规划变量,向外界传递了一个清晰的信号:智能体工作负载的扩展,必须建立在庞大的CPU基础设施之上。
美国银行预测,到2030年,全球CPU市场规模有望从目前的270亿美元翻倍至600亿美元。这多出来的份额,几乎全部将由AI驱动。
我们正在见证一种全新的基础设施开始扩张:大厂不再只堆GPU,而是同步扩张一整层“CPU调度基础设施”,专门为AI智能体提供运行支撑。
英特尔与谷歌的联手,以及马斯克对定制芯片的重金投入,都在证明一个事实:AI竞赛的制胜点正在前移。当算力不再稀缺,谁能最先解决系统级的“瓶颈”,谁才能在这场万亿级的游戏中笑到最后。
 服务热线 027-83317177
服务热线 027-83317177 